Introduction
This is a collection of notes on programming languages, frameworks and other computer science topics that I am writing to keep track of my studies. It is a work in progress.
Notes on C
Table of Contents
Basics
The minimal "hello world" C program:
#include <stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
Any position that is not listed in the initializer is set to 0. A[2] == 0.0
Don’t compare to 0, false, or true. Also, all scalars have a truth value. An integer or floating point 0 will always evaluate to false.
// GOOD
bool b = true;
if ( b ) {
// do something
}
// BAD
bool b = true;
if (( b != false ) == true ) {
// do something
}
The scalar types:
| Name | Where | printf |
|---|---|---|
| size_t | <stddef.h> | "%zu" "%zx |
| double | Built in | "%e" "%f" "%g" "%a" |
| signed | Built in | "%d" |
| unsigned | Built in | "%u" "%x" |
| bool | <stdbool.h> | "%d" |
| ptrdiff_t | <stddef.h> | "%td" |
| char const* | Built in | "%s" |
| char | Built in | "%c" |
| void* | Built in | "%p" |
| unsigned char | Built in | "%hhu" "%02hhx" |
size_t is any integer on the interval [0, SIZE_MAX], as defined on stdint.h.
Best Practice: Never modify more than one object in a statement.
Best Practice: Never declare various pointers or arrays on the same line to avoid errors.
Ternary operator:
// Pattern:
// (boolean_expression) ? if_true : if_false;
size_t size_min(size_t a , size_t b) {
return ( a < b ) ? a : b;
}
Attention: in an expression such as f(a) + g(b), there is no pre-established order specifying
whether f(a) or g(b) is to be computed first. If either the function f or g works with side effects
(for instance, if f modifies b behind the scenes), the outcome of the expression will depend on the
chosen order. The same holds for function arguments:
printf("%g and %g\n", f(a), f(b));
Best Practice: Functions that are called inside expressions should not have side effects.
Every type in C is either an object type or a function type.
C is call-by-value. When you provide an argument to a function, the value of that argument is copied into a distinct variable for use within the function.
Scopes can be nested, with inner and outer scopes. For example, you can have a block scope inside another block scope, and every block scope is defined within a file scope. The inner scope has access to the outer scope, but not vice versa. If you declare the same identifier in both the inner scope and an outer scope, the identifier declared in the outer scope is hidden by the identifier within the inner scope, which takes precedence. In this case, naming the identifier will refer to the object in the inner scope; the object from the outer scope is hidden and cannot be referenced by its name.
Scope and lifetime are different. Scope applies to identifiers, whereas lifetime applies to objects. The scope of an identifier is the code region where the object denoted by the identifier can be accessed by its name. The lifetime of an object is the time period for which the object exists.
Automatic lifetimes are declared within a block or as a function parameter. The lifetime of these objects begins when the block in which they’re declared begins execution, and ends when execution of the block ends. If the block is entered recursively, a new object is created each time, each with its own storage.
Objects declared in file scope have static storage duration. The lifetime of these objects is the entire execution of the program, and their stored value is initialized prior to program startup. One can use static to declare a variable within a block scope to have a static lifetime. These objects persist after the function has exited.
Best Practice: Never declare functions with an empty parameter list in C. Always use void in the parameter like so:
int my_function(void);
Enums
Allows you to define a type that assigns names (enumerators) to integer values in cases with an enumerable set of constant val- ues.
enum day { sun, mon, tue, wed, thu, fri, sat };
enum cardinal_points { north = 0, east = 90, south = 180, west = 270 };
enum months { jan = 1, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec };
Pointers
int* ip;
char* cp;
void* vp;
int i = 17;
int* ip = &i;
The & operator takes the address of an object or function.
The * operator converts a pointer to a type into a value of that type. It denotes indirection and operates only on pointers.
Arrays
A contiguously allocated sequence of objects that all have the same element type.
int ia[11];
float* afp[17];
int matrix[3][5];
Initializing an array:
double A[5] = {
[0] = 9.0,
[1] = 2.9,
[4] = 3.E+25,
[3] = .00007,
};
// A[2] is initialized as 0.0
Structs
A struct contains sequentially allocated member objects. One can reference members of a struct by using the struct member operator (.). If you have a pointer to a struct, you can reference its members with the struct pointer operator (->).
typedef struct vec2 { float x, y; } vec2;
vec2 v0 = {1.0f, 2.0f};
vec2 v1 = {.x = 1.0f, .y = 2.0f};
vec2 v2 = {.y = 2.0f}; // missing struct members are set to zero
// Inside functions, runtime-variable values can be used for initialization:
float get_x(void) {
return 1.0f;
}
void bla(void) {
vec2 v0 = { .x = get_x(), .y = 2.0f };
}
// But this doesn't work:
vec2 v0;
// this doesn't work
v0 = {1.0f, 2.0f};
// instead a type hint is needed:
v0 = (vec2) {1.0f, 2.0f};
Unions
Union types are similar to structures, except that the memory used by the member objects overlaps. Unions can contain an object of one type at one time, and an object of a different type at a different time, but never both objects at the same time, and are primarily used to save memory.
Qualifiers
Types can be qualified by using one or more of the following qualifiers: const, volatile, and restrict.
const: not modifiable. Will be placed in read-only memory by the compiler, and any attempt to write to them will result in a runtime error.volatile: values stored in these objects may change without the knowledge of the compiler. For example, every time the value from a real-time clock is read, it may change, even if the value has not been written to by the C program. Using a volatile-qualified type lets the compiler know that the value may change, and ensures that every access to the real-time clock occurs (otherwise, an access to the real-time clock may be optimized away or replaced by a previously read and cached value).restrict: Used to promote optimization. Objects indirectly accessed through a pointer frequently cannot be fully optimized because of potential aliasing, which occurs when more than one pointer refers to the same object. Aliasing can inhibit optimizations, because the compiler can’t tell if portions of an object can change values when another apparently unrelated object is modified, for example.
Preprocessor
Defines a macro as 0 and an empty macro:
#define __MACRO__ 0
#define __MACRO2__
Checks if a macro is defined. If it is, throws an error (the error stops the compilation):
#ifdef __MACRO__
#error "Error!"
#endif
Checks if a macro is not defined. If it isn't, defines it:
#ifndef __MACRO__
#define __MACRO__
#endif
Some Best Practices
- Enable all warnings: -Wall and -Wextra on GCC and Clang
- Wrap your structs in a typedef:
typedef struct bla{
int a, b, c;
} bla;
// Attention: the POSIX standard reserves the ‘_t’ postfix for its own type names to prevent collisions with user types.
- Use void to indicate that a function does not receive arguments:
// GOOD
void my_func(void) {
...
}
// BAD
void my_func() {
...
}
- Don’t be afraid to pass and return structs by value:
typedef struct float2{ float x, y; } float2;
float2 addf2(float2 v0, float2 v1) {
return (float2) { v0.x + v1.x, v0.y + v1.y };
}
...
float2 v0 = {1.0f, 2.0f};
float2 v1 = {3.0f, 4.0f};
float2 v3 = addf2(v0, v1);
...
// You can also move the initialization of the two inputs right into the function call:
float2 v3 = addf2((float2){ 1.0f, 2.0f }, (float2){ 3.0f, 4.0f });
Some Headers
- stdint.h: defines integer types with certain widths.
- tgmath.h: defines type generic math functions, for both real and complex numbers.
Bibliography
- SEACORD, Robert. Effective C: an introduction to professional C programming. No Starch Press. 2020.
Notes on C++
Table of Contents
Basics
The minimal "hello world" C++ program:
#include <iostream>
int main()
{
std::cout<<"Hello, World!\n";
return 0;
}
The #include directive imports a library to be used. The main function is the entry point of the program and returns an integer upon successful completion. Blocks of code that perform some well defined action should be encapsulated on a function. That function would then be called on main(). A function must be declared before being used. The declaration follows this syntax:
Node* next_node(); // Receives no argument, returns pointer to Node
void call_number(int); // Receives an int, returns nothing
double exp(double); // Receives a double, returns a double.
There can be more than one argument. The types of the arguments and of the return are checked at compile time. The code that makes up a software must be comprehensible because this is the first step to maintainability. To make code more comprehensible, we must divide its tasks into functions. That way, we will have a basic vocabulary for data (types, both built-in and user defined) and for actions on that data (functions). Encapsulating a specific action into a function, forces us to not repeat ourselves (DRY) and to document that action's dependencies. If a function with the same name is declared with different arguments, the compiler will accept all of them and use the function corresponding to the type used. This allows us to change the behavior of an action based on the type of the data we are dealing with. Attention to the fact that the declarations cannot be ambiguous. If so, the compiler will throw an error. Another point is that if a set of functions have the same name, they should have the same semantics, i.e., they should perform the same action. Example:
// This is called function overloading
void sum(int, int);
void sum(double, double);
void use()
{
sum(2, 2);
sum(2.7, 3.14);
}
Every object in the language has a type. An object is a portion of memory that holds a value of the given type. A value is a set of bits that are interpreted according to the type. Some built-in types are bool, char, int and double. Int variables' representation default to decimal (42) but can also be declared as binary (0b1010), hexadecimal (0x04AF) or octal (0432). The usual arithmetic, comparison, logical and modification operations are present:
| Arithmetic | Comparison | Logical | Modification |
|---|---|---|---|
| x + y | x == y | x && y | x += y |
| x - y | x != y | x || y | x -= y |
| x * y | x < y | !x | ++x |
| x / y | x > y | --x | |
| x % y | x <= y | x *= y | |
| x >= y | x /= y | ||
| x %= y |
Attention to the fact that C++ makes implicit conversion on basic types:
void my_function()
{
double d = 3.14;
int i = 5;
d = d + i; // d is 8.14 here
i = d * i; // i is 15 here.
// The resulting multiplication is 15.7,
// but the value is truncated to fit an int
}
There are two forms of variable initialization, "=" or "{}":
double d = 3.14;
double d2 {2.7};
// Vector of ints
vector<int> v {1, 2, 3};
The "=" is a tradition from C. "{}" is preferred because it avoids implicit conversions:
int a = 4.8; // a is 4 here
int b {4.8}; // Error
If the data is coming from the user, for example, implicit conversions are a recipe for disaster, if not checked. The type of a variable can be deduced by the compiler with the "auto" keyword. My opinion is that auto should only be used when the types are very long (as they usually are with templates). Explicit (short) types help with code readability.
auto a = 4.8;
auto b {4.8}; // Both a and b are double
-> 1.5
User-Defined Types
Modularity
Classes
Constructors
A constructor without parameters or with default parameters set is called a default constructor. It is a constructor which can be called without arguments:
class MyClass
{
public:
MyClass()
{
std::cout << "Default constructor invoked.\n";
}
};
int main()
{
MyClass o; // invoke a default constructor
}
// Default arguments
class MyClass
{
public:
MyClass(int x = 123, int y = 456)
{
std::cout << "Default constructor invoked.\n";
}
};
int main()
{
MyClass o; // invoke a default constructor
}
// If a default constructor is not explicitly defined in the code, the compiler will generate a default constructor.
// Constructors are invoked when object initialization takes place. They can’t be invoked directly.
Member initializer list:
class MyClass
{
public:
int x, y;
MyClass(int xx, int yy)
: x{ xx }
, y{ yy } // member initializer list
{
}
};
int main()
{
MyClass o{ 1, 2 }; // invoke a user-defined constructor
std::cout << o.x << ' ' << o.y;
}
Copy Constructors
When we initialize an object with another object of the same class, we invoke a copy constructor. If we do not supply our copy constructor, the compiler generates a default copy constructor.
class MyClass
{
private:
int x, y;
public:
MyClass(int xx, int yy) : x{ xx }, y{ yy }
{
}
};
int main()
{
MyClass o1{ 1, 2 };
MyClass o2 = o1; // default copy constructor invoked
}
A user defined copy constructor has this signature: MyClass(const MyClass& rhs)
class MyClass
{
private:
int x, y;
public:
MyClass(int xx, int yy) : x{ xx }, y{ yy }
{
}
MyClass(const MyClass& rhs)
: x { rhs.x }
, y { rhs.y }
{
}
};
int main()
{
MyClass o1{ 1, 2 };
MyClass o2 = o1; // user copy constructor invoked
}
Copy Assignment
When an object is created on one line and then assigned to in the next line, it then uses the copy assignment operator to copy the data from another object:
MyClass from, to;
to = from; // copy assignment
A copy assignment operator is of the following signature: MyClass& operator=(const MyClass& rhs)
class MyClass
{
public:
MyClass& operator=(const MyClass& rhs)
{
// implement the copy logic here
return *this;
}
};
// The overloaded = operators must return a dereferenced this pointer at the end.
Move Constructor
We can move the data from one object to the other. We call it a move semantics.
Operations
Templates
Generic Programming
Standard Library
Strings and Regex
To accept a string from standard input, use std::getline(read_from, into):
std::string s;
std::cout << "Enter string: ";
std::getline(std::cin, s);
To create a substring from a string, use the method .substring(starting_index, length):
std::string s = "Hello World";
std::string sub_s = s.substr(6, 5);
To find a substring in a given string, use the method .find(). If the method finds, it returns the position of the first found substring (the index of the first char of the substring). If the method doesn't find, it returns std::string:npos. The return type of the function is std::string::size_type:
std::string s = "Hello World";
std::string search_for = "World";
std::string::size_type found = s.find(search_for);
I/O
TODO
Containers
TODO
Algorithms
TODO
Utilities
TODO
Numerics
TODO
Concurrency
TODO
References
- Bjarne Stroustrup. A Tour of C++. Pearson Education. 2018.
- Slobodan Dmitrovic. Modern C++ for Absolute Beginners. 2020.
Notes on Cython
Table of Contents
Compilation
Using distutils with cythonize
Consider a fib.pyx Cython source code. Our goal is to use distutils to create a compiled extension module (fib.so on Mac OS X or Linux and fib.pyd on Windows). For that, we use a setup.py file like so:
from distutils.core import setup
from Cython.Build import cythonize
setup(name='Fibonacci App',
ext_modules=cythonize('fib.pyx',
nthreads=4,
force=False,
annotate=True,
compiler_directives={'binding': True},
language_level="3"))
The arguments of the function cythonize can be seen here. The most important ones are explained below:
- The first argument is the name of the Cython files. It can also be a glob pattern such as
src/*.pyx; nthreads: The number of concurrent builds for parallel compilation (requires the multiprocessing module);force: Forces the recompilation of the Cython modules, even if the timestamps don’t indicate that a recompilation is necessary. Default is False;annotate: If True, will produce a HTML file for each of the .pyx or .py files compiled. The HTML file gives an indication of how much Python interaction there is in each of the source code lines, compared to plain C code. It also allows you to see the C/C++ code generated for each line of Cython code. Default is False;compiler_directives: Allows to set compiler directives. More information here;language_level: The level of the Python language.3is for Python 3.
These two function calls succinctly demonstrate the two stages in the pipeline: cythonize calls the cython compiler on the .pyx source file or files, and setup compiles the generated C or C++ code into a Python extension module. A C compiler, such as gcc, clang or MSVC is necessary at compile time.
To build on Linux and MacOS, run:
python3 setup.py build_ext --inplace
The build_ext argument is a command instructing distutils to build the Extension object or objects that the cythonize call created. The optional --inplace flag instructs distutils to place each extension module next to its respective Cython .pyx source file.
On Windows:
python setup.py build_ext --inplace --compiler=msvc
If you use setuptools instead of distutils, the default action when running python3 setup.py install is to create a zipped egg file which will not work with cimport for pxd files when you try to use them from a dependent package. To prevent this, include zip_safe=False in the arguments to setup().
One can also set compiler options in the setup.py, before calling cythonize(), like so:
from distutils.core import setup
from Cython.Build import cythonize
from Cython.Compiler import Options
Options.embed = True
setup(name='Fibonacci App',
ext_modules=cythonize('fib.pyx',
nthreads=4,
force=False,
annotate=True,
compiler_directives={'binding': True},
language_level="3"))
The embed option embeds the Python interpreter, in order to make a standalone executable. This will provide a C function which initialises the interpreter and executes the body of this module. More options here.
Typing
Typing variables
Untyped dynamic variables are declared and behave exactly like Python variables:
a = 42
Statically typed variables are declared like so:
cdef int a = 42
cdef size_t len
cdef double *p
cdef int arr[10]
and behave like C variables.
It is possible to mix both kinds of variables if there is a trivial correspondence between the types, like C and Python ints:
# C variables
cdef int a, b, c
# Calculations using a, b, and c...
# Inside a Python tuple
tuple_of_ints = (a, b, c)
In Python 3, all int objects have unlimited precision. When converting integral types from Python to C, Cython generates code that checks for overflow. If the C type cannot represent the Python integer, a runtime OverflowError is raised.
A Python float is stored as a C double. Converting a Python float to a C float may truncate to 0.0 or positive or negative infinity, according to IEEE 754 conversion rules.
The Python complex type is stored as a C struct of two doubles. Cython has float complex and double complex C-level types, which correspond to the Python complex type.
We can also use cdef to statically declare variables with a Python type. We can do this for the built-in types like list, tuple, and dict and extension types like NumPy arrays:
cdef list particles, modified_particles
cdef dict names_from_particles
cdef str pname
cdef set unique_particles
The more static type information we provide, the better Cython can optimize the result.
C Functions
When used to define a function, the cdef keyword creates a function with C-calling semantics. A cdef function’s arguments and return type are typically statically typed, and they can work with C pointer objects, structs, and other C types that cannot be automatically coerced to Python types. It is helpful to think of a cdef function as a C function that is defined with Cython’s Python-like syntax.
cdef long factorial(long n):
if n <= 1:
return 1
return n * factorial(n - 1)
A function declared with cdef can be called by any other function (def or cdef) inside the same Cython source file. However, Cython does not allow a cdef function to be called from external Python code. Because of this restriction, cdef functions are typically used as fast auxiliary functions to help def functions do their job.
If we want to use factorial from Python code outside of this extension module, we need a minimal def function that calls factorial internally:
def wrap_factorial(n):
return factorial(n)
One limitation of this is that wrap_factorial and its underlying factorial are restricted to C integral types only, and do not have the benefit of Python’s unlimited-precision integers. This means that wrap_factorial gives erroneous results for arguments larger than some small value, depending on how large an unsigned long is on your system. We always have to be aware of the limitations of the C types.
C Functions with Automatic Python Wrappers
A cpdef function combines features from cdef and def functions: we get a C-only version of the function and a Python wrapper for it, both with the same name. When we call the function from Cython, we call the C-only version; when we call the function from Python, the wrapper is called.
cpdef long factorial(long n):
if n <= 1:
return 1
return n * factorial(n - 1)
A cpdef function has one limitation, due to the fact that it does double duty as both a Python and a C function: its arguments and return types have to be compatible with both Python and C types.
Both cdef and cpdef can be given an inline hint that the C compiler can use or ignore, depending on the situation:
cpdef inline long factorial(long n):
if n <= 1:
return 1
return n * factorial(n - 1)
The inline modifier, when judiciously used, can yield performance improvements, especially for small inlined functions called in deeply nested loops, for example.
Exception Handling
A def function always returns some sort of PyObject pointer at the C level. This invariant allows Cython to correctly propagate exceptions from def functions without issue. Cython’s other two function types (cdef and cpdef) may return a non-Python type, which makes some other exception-indicating mechanism necessary. Example:
cpdef int divide_ints(int i, int j):
return i / j
To correctly propagate the exception that occurs when j is 0, Cython provides an except clause:
cpdef int divide_ints(int i, int j) except? -1:
return i / j
The except? -1 clause allows the return value -1 to act as a possible sentinel that an exception has occurred. If divide_ints ever returns -1, Cython checks if the global exception state has been set, and if so, starts unwinding the stack.
In this example we use a question mark in the except clause because -1 might be a valid result from divide_ints, in which case no exception state will be set. If there is a return value that always indicates an error has occurred without ambiguity, then the question mark can be omitted.
C structs, unions, enums an typedefs
The following C constructs:
struct mycpx {
int a;
float b;
};
union uu {
int a;
short b, c;
};
enum COLORS {ORANGE, GREEN, PURPLE};
Can be declared on Cython like this:
cdef struct mycpx:
float real
float imag
cdef union uu:
int a
short b, c
cdef enum COLORS:
ORANGE, GREEN, PURPLE
We can combine struct and union declarations with ctypedef, which creates a new type alias for the struct or union:
ctypedef struct mycpx:
float real
float imag
ctypedef union uu:
int a
short b, c
To declare and initialize:
cdef mycpx a = mycpx(3.1415, -1.0)
# Or
cdef mycpx b = mycpx(real=2.718, imag=1.618034)
# Or
cdef mycpx zz
zz.real = 3.1415
zz.imag = -1.0
# Or, structs can be assigned from a Python dictionary (with CPython overhead):
cdef mycpx zz = {'real': 3.1415, 'imag': -1.0}
Efficient Loops
Considering this Python for loop over a range:
n = 100
# ...
for i in range(n):
# ...
Its cythonized version that would produce the best performing C code is:
cdef unsigned int i, n = 100
for i in range(n):
# ...
Extension Types
A Python class such as:
class Particle():
def __init__(self, m, p, v):
self.mass = m
self.position = p
self.velocity = v
def get_momentum(self):
return self.mass * self.velocity
Would be cythonized as:
cdef class Particle():
cdef double mass, position, velocity
def __init__(self, m, p, v):
self.mass = m
self.position = p
self.velocity = v
def get_momentum(self):
return self.mass * self.velocity
To make an attribute readonly (for a Python caller):
cdef class Particle():
cdef readonly double mass
cdef double position, velocity
# ...
mass will be readable and not writable by the Python caller, but position and velocity will be completely private.
cdef class Particle():
cdef readonly double mass
cdef public double position
cdef double velocity
# ...
Here, position will be both readable and writable by the Python caller.
If C-level allocations and deallocations must occur, then use the __cinit__ and __dealloc__ methods:
cdef class Matrix:
cdef:
unsigned int nrows, ncols
double *_matrix
def __cinit__(self, nr, nc):
self.nrows = nr
self.ncols = nc
self._matrix = <double*>malloc(nr * nc * sizeof(double))
if self._matrix == NULL:
raise MemoryError()
def __dealloc__(self):
if self._matrix != NULL:
free(self._matrix)
You can cast a Python object to a static object:
# p is a Python object that may be a Particle
cdef Particle static_p = p
# Or, with the possibility of segfault if p is not a particle:
<Particle>p
# Or, safelly, but with overhead:
<Particle?>p
None can be passed as argument for functions that receive static type. This will lead to segfaults. To protect against it:
def dispatch(Particle p not None):
print p.get_momentum()
print p.velocity
Wrapping C++
TODO
Profiling
TODO
Typed Memoryviews
TODO
Parallelism
TODO
References
- Kurt W. Smith. Cython. 1st Edition. O’Reilly.
- Official Cython’s Documentation
Notes on Julia
Julia is a high-level, general-purpose dynamic programming language, most commonly used for numerical analysis and computational science. Distinctive aspects of Julia's design include a type system with parametric polymorphism and the use of multiple dispatch as a core programming paradigm, efficient garbage collection, and a just-in-time (JIT) compiler (with support for ahead-of-time compilation).
Julia Deep Dive
Table of Contents
- Julia Deep Dive
Basics
The minimal "hello world" program:
# Single line comment
#=
Multi-line comment
=#
println("Hello, World!")
Indentation doesn't matter. Indexing starts at 1, like Matlab and Octave. In the REPL, by pressing "]" you can enter the "package mode", where you can write commands that manage the packages you have or want. Some commands:
status: Retrieves a list with name and versions of locally installed packagesupdate: Updates your local index of packages and all your local packages to the latest versionadd myPkg: Automatically downloads and installs a packagerm myPkg: Removes a package and all its dependent packages that has been installed automatically only for itadd pkgName#master: Checkouts the master branch of a package (and free pkgName returns to the released version)add pkgName#branchName: Checkout a specific branchadd git@github.com:userName/pkgName.jl.git: Checkout a non registered pkg
To use a package on a Julia script, write using [package] at the beginning of the script. To use a package without populating the namespace, write import [package]. But then, you will have to use the functions as [package].function(). You can also include local Julia scripts as such: include("my_script.jl").
I think that using [package] is bad practice because it pollutes the namespace. The best way to import a package is this:
# Importing the JSON package through an alias
import JSON as J
# Using:
J.print(Dict("Hello, " => "World!"))
A particular class of variable names is one that contains only underscores. These identifiers can only be assigned values, which are immediately discarded, and cannot therefore be used to assign values to other variables (i.e., they cannot be used as rvalues) or use the last value assigned to them in any way.
Data Types and Structures
Some built-in data types and structures of the Julia language:
Scalar Types
The usual scalar types are present: Int64, UInt128, BigInt, Float64, Char and Bool.
Const values
Constant values are declared as such:
const foo = 1234
Basic Math
Complex numbers can be defined like so, with im being the square root of -1:
a = 1 + 2im
Exact integer division can be done like this:
a = 2 // 3
All standard basic mathematical arithmetic operators are supported (+, -, *, /, %, ^). Mathematical constants can be used like so:
MathConstants.e
MathConstants.pi
Natural exponentiation can be done like this:
a = exp(b)
Strings
Strings are immutable. We use single quote for chars and double quote for strings. A string on a single row can be created using a single pair of double quotes, while a string on multiple rows can use a triple pair of double quotes:
a = "a string"
b = "a string\non multiple rows\n"
c = """
a string
on multiple rows
"""
Some string operations are also present, like:
split: Separates string into other strings based on a char. Default char is whitespace.join([string1, string2], ""): Concatenates strings with a certain string.replace(s, "toSearch" => "toReplace"): Replaces occurrences on the string s.strip(s): Remove leading and trailing whitespaces.
Other ways to concatenate strings:
- Concatenation operator:
*; - Function
string(string1,string2,string3); - Interpolate string variables in a bigger one using the dollar symbol:
a = "$str1 is a string and $(myobject.int1) is an integer".
To convert strings representing numbers to integers or floats, use myInt = parse(Int64,"2017"). To convert integers or floats to strings, use myString = string(123).
You can broadcast a function to work over a collection (instead of a scalar) using the dot (.) operator. For example, to broadcast parse to work over an array:
myNewList = parse.(Float64,["1.1","1.2"])
Arrays
Arrays are N-dimensional mutable containers. Ways to create one:
a = []ora = Int64[]ora = Array{T,1}()ora = Vector{T}(): Empty array. Array{} is the constructor, T is the type and Vector{} is an alias for 1 dimensional arrays.a = zeros(5)ora = zeros(Int64,5)ora = ones(5): Array of zeros (or ones)a = fill(j, n): n-element array of identical j elementsa = rand(n): n-element array of random numbersa = [1,2,3]: Explicit construction (column vector).a = [1 2 3]: Row vector (this is a two-dimensional array where the first dimension is made of a single row)a = [10, "foo", false]: Can be of mixed types, but will be much slower
If you need to store different types on a data structure, better to use an Union: a = Union{Int64,String,Bool}[10, "Foo", false].
Some operations on arrays:
a[1]: Access element.a[from:step:to]: Slicecollect(myiterator): Transforms an iterator in an array.y = vcat(2015, 2025:2028, 2100): Initialize an array expanding the elements. 2025:2028 means [2025, 2026, 2027, 2028].push!(a,b): Append b to the end of aappend!(a,b): Append the elements of b to the end of a. If b is scalar, append b to the end of a.a = [1,2,3]; b = [4,5]; c = vcat(1,a,b): Concatenation of arrays.pop!(a): Remove element from the end of a.popfirst!(a): Remove first element of a.deleteat!(a, pos): Remove element at position pos from array a.pushfirst!(a,b): Add b at the beginning of array a.sort!(a) or sort(a): Sorting, depending on whether we want to modify or not the original array.unique!(a) or unique(a): Remove duplicatesa[end:-1:1]: Reverses array a.in(1, a): Checks for existence.length(a): Length of array.a...: The “splat” operator. Converts the values of an array into function parametersmaximum(a) or max(a...): Maximum value. max returns the maximum value between the given arguments.minimum(a) or min(a...): Minimum value. min returns the minimum value between the given arguments.isempty(a): Checks if an array is empty.reverse(a): Reverses an array.sum(a): Return the summation of the elements of a.cumsum(a): Return the cumulative sum of each element of a (returns an array).empty!(a): Empty an array (works only for column vectors, not for row vectors).b = vec(a): Transform row vectors into column vectors.shuffle(a) or shuffle!(a): Random-shuffle the elements of a (requiresusing Randombefore).findall(x -> x == value, myArray): Find a value in an array and return its indexes.enumerate(a): Get (index,element) pairs. Return an iterator to tuples, where the first element is the index of each element of the array a and the second is the element itself.zip(a,b): Get (a_element, b_element) pairs. Return an iterator to tuples made of elements from each of the arguments
Functions that end in '!' modify their first argument.
Map applies a function to every element in the input arrays:
map(func, my_array)
Filter takes a collection of values, xs, and returns a subset, ys, of those
values. The specific values from xs that are included in the resulting ys are deter-
mined by the predicate p. A predicate is a function that takes some value and always returns a Boolean value:
ys = filter(p, xs)
Reduce takes some binary function, g, as the first argument, and then uses this function to combine the elements in the collection, xs, provided as the second argument:
y = reduce(g, xs)
Mapreduce can be understood as reduce(g, map(f, xs)).
Multidimensional and Nested Arrays
A matrix is an array of arrays that have the same length. The main difference between a matrix and an array of arrays is that, with a matrix, the number of elements on each column (row) must be the same and rules of linear algebra apply.
Attention: Julia is column-major
Ways to create one:
a = Matrix{T}()a = Array{T}(undef, 0, 0, 0)a = [[1,2,3] [4,5,6]]: [[elements of the first column] [elements of the second column] ...].a = hcat(col1, col2). By the columns.a = [1 4; 2 5; 3 6]: [elements of the first row; elements of the second row; ...].a = vcat(row1, row2): By the rows.a = zeros(2,3)ora = ones(2,3): A 2x3 matrix filled with zeros or ones.a = fill(j, 2, 3): A 2x3 matrix of identical j elementsa = rand(2, 3): A 2x3 matrix of random numbers
Attention to the difference:
a = [[1,2,3],[4,5,6]]: creates a 1-dimensional array with 2-elements.a = [[1,2,3] [4,5,6]]: creates a 2-dimensional array (a matrix with 2 columns) with three elements (scalars).
Access the elements with a[row,col].
You can also make a boolean mask and apply to the matrix:
a = [[1,2,3] [4,5,6]]
mask = [[true,true,false] [false,true,false]]
println(a[mask])
# Will print [1, 2, 5]. Always flattened.
Other useful operations:
size(a): Returns a tuple with the sizes of the n dimensions.ndims(a): Returns the number of dimensions of the array.a': Transpose operator.reshape(a, nElementsDim1, nElementsDim2): Reshape the elements of a in a new n-dimensional array with the dimensions given.dropdims(a, dims=(dimToDrop1,dimToDrop2)): Remove the specified dimensions, provided that the specified dimension has only a single element
These last three operations performe only a shallow copy (a view) on the matrix, so if the underlying matrix changes, the view also changes. Use collect(reshape/dropdims/transpose) to force a deep copy.
Tuples
Tuples are an immutable collection of elements. Initialize with a = (1,2,3) or a = 1,2,3. Tuples can be unpacked like so: var1, var2 = (x,y). And you can convert a tuple into a vector like this: v = collect(a).
Named Tuples
Named tuples are immutable collections of items whose position in the collection (index) can be identified not only by their position but also by their name.
nt = (a=1, b=2.5): Define a NamedTuplent.a: Access the elements with the dot notationkeys(nt): Return a tuple of the keysvalues(nt): Return a tuple of the valuescollect(nt): Return an array of the valuespairs(nt): Return an iterable of the pairs (key,value). Useful for looping:for (k,v) in pairs(nt) [...] end
Dictionaries
Dictionaries are mutable mappings from keys to values. Ways to create one:
mydict = Dict{T,U}()mydict = Dict('a'=>1, 'b'=>2, 'c'=>3)
Useful operations:
mydict[key] = value: Add pairs to the dictionarymydict[key]: Look up value. If it doesn't exist, raises error.get(mydict,'a',0): Look up value with a default value for non-existing key.keys(mydict): Get all keys. Results in an iterator. Use collect() to transform into array.values(mydict): Iterator of all the values.haskey(mydict, 'a'): Checks if a key exists.in(('a' => 1), mydict): Checks if a given key/value pair exists.delete!(amydict,'akey'): Delete the pair with the specified key from the dictionary.
You can iterate over both keys and values:
for (k,v) in mydict
println("$k is $v")
end
Sets
A set is a mutable collection of unordered and unique values. Ways to create one:
a = Set{T}(): Empty seta = Set([1,2,2,3,4]): Initialize with valuespush!(s, 5): Add elementsdelete!(s,1): Delete elementsintersect(set1,set2),union(set1,set2),setdiff(set1,set2): Intersection, union, and difference.
Memory and Copy
Shallow copy (copy of the memory address only) is the default in Julia. Some observations:
a = b: This is a name binding. It binds the entity referenced bybto theaidentifier. Ifbrebinds to some other object,aremains referenced to the original object. If the object referenced bybmutates, so does those referenced bya.- When a variable receives other variable: Basic types (Float64, Int64, String) are deep copied. Containers are shallow copied.
copy(x): Simple types are deep copied, containers of simple types are deep copied, containers of containers, the content is shadow copied (the content of the content is only referenced, not copied).deepcopy(x): Everything is deep copied recursively.
Observations on types:
You can check if two objects have the same values with == and if two objects are actually the same with ===.
To cast an object into a different type:
convertedObj = convert(T,x)
Random Numbers
rand(): Random float in [0,1].rand(a:b): Random integer in [a,b].rand(a:0.01:b): Random float in [a,b] with "precision" to the second digit.rand(2,3): Random 2x3 matrix.rand(DistributionName([distribution parameters])): Random float in [a,b] using a particular distribution (Normal, Poisson,...). Requires the Distributions package.rand(Uniform(a,b)): Random float in [a,b] using an uniform distribution.import Random:seed!; seed!(1234): Sets a seed.
Basic Syntax
The typical control flow is present:
# 1 and 5 are included on this range
for i = 1:5
println(i)
end
for j in [1, 2, 3]
println(j)
end
# Nested loops:
for i = 1:2, j = 3:4
println((i, j))
end
i = 0
while i < 5
println(i)
global i += 1
end
if x < y
println("x is less than y")
elseif x > y
println("x is greater than y")
else
println("x is equal to y")
end
There are list comprehensions:
[myfunction(i) for i in [1,2,3]]
[x + 2y for x in [10,20,30], y in [1,2,3]]
mydict = Dict()
[mydict[i]=value for (i, value) in enumerate(mylist)]
# enumerate returns an iterator to tuples with the index and the value of elements in an array
[students[name] = sex for (name,sex) in zip(names,sexes)]
# zip returns an iterator of tuples pairing two or multiple lists, e.g. [("Marc","M"),("Anne","F")]
map((n,s) -> students[n] = s, names, sexes)
# map applies a function to a list of arguments
The ternary operator is present:
a ? b : c
# If a is true, then b, else c
The usual logic operators exist:
- And:
&& - Or:
|| - Not:
!
Functions
Functions can be declared like so:
function f(x)
x+2
end
Function arguments are normally specified by position (positional arguments). However, if a semicolon (;) is used in the parameter list of the function definition, the arguments listed after that semicolon must be specified by name (keyword arguments).
function func(a,b=1;c=2)
# blabla
end
# Optionally restrict the types of argument the function should accept by annotating the parameter with the type:
function func(a::Int64,b::Int64=1;c::Int64=2)
# blabla
end
Function that can operate on some types but not others:
# This function can operate on Float64 or on a Vector of Float64.
function func(par::Union{Float64, Vector{Float64}})
# In the body we check the type using typeof()
end
Function with variable number of arguments:
# The splat operator (...) can specify a variable number of arguments in the parameter declaration
function func(a, args...)
# The parameter that uses the ellipsis must be the last one
# In the body we use args as an iterator
end
Julia has multiple-dispatch. If you declare the same function with different arguments, the compiler will choose the correct function to call based on the arguments you passed. You can also do type parametrization on functions:
function f(x::T)
x+2
end
myfunction(x::T, y::T2, z::T2) where {T <: Number, T2} = 5x + 5y + 5z
Functions are objects that can be assigned to new variables, returned, or nested:
f(x) = 2x # define a function f inline
a = f(2) # call f and assign the return value to a
a = f # bind f to a new variable name (it's not a deep copy)
a(5) # call again the (same) function
Functions work on new local variables, known only inside the function itself. Assigning the variable to another object will not influence the original variable. But if the object bound with the variable is mutable (e.g., an array), the mutation of this object will apply to the original variable as well:
function f(x,y)
x = 10
y[1] = 10
end
x = 1
y = [1,1]
# x will not change, but y will now be [10,1]
f(x,y)
Functions that change their arguments have their name, by convention, followed by an '!'. The first parameter is, still by convention, the one that will be modified.
Anonymous functions can be declared like so:
(x, y) -> x^2 + 2y - 1
# you can assign an anonymous function to a variable.
You can broadcast a function to work over all the elements of an array:
myArray = broadcast(i -> replace(i, "x" => "y"), myArray)
# Or like this:
f = i -> replace(i, "x" => "y")
myArray = f.(myArray)
Functions whose name is a singular symbol can be used on an infix or prefix form:
5 + 3
+(5, 3)
Custom Types
There are two type operators:
- The
::operator is used to constrain an object of being of a given type. For example,a::Bmeans “a must be of type B”. - The
<:operator has a similar meaning, but it’s a bit more relaxed in the sense that the object can be of any subtypes of the given type. For example,A<:Bmeans “A must be a subtype of B”, that is, B is the “parent” type and A is its “child” type.
You can define structures like this:
# Structs are immutable by default. Hence the mutable keyword.
# Immutable structs are much faster.
mutable struct MyStruct
property1::Int64
property2::String
end
# Parametrized:
mutable struct MyStruct2{T<:Number}
property1::Int64
property2::String
property3::T
end
# Instantiating and accessing attribute:
myObject = MyStruct(20,"something")
a = myObject.property1 # 20
Attention to this:
a::B: Means "a must be of type B".A<:B: Means "A must be a subtype of B".
An example of object orientation in Julia:
struct Person
myname::String
age::Int64
end
struct Shoes
shoesType::String
colour::String
end
struct Student
s::Person
school::String
shoes::Shoes
end
function printMyActivity(self::Student)
println("I study at $(self.school) school")
end
struct Employee
s::Person
monthlyIncomes::Float64
company::String
shoes::Shoes
end
function printMyActivity(self::Employee)
println("I work at $(self.company) company")
end
gymShoes = Shoes("gym","white")
proShoes = Shoes("classical","brown")
Marc = Student(Person("Marc",15),"Divine School",gymShoes)
MrBrown = Employee(Person("Brown",45),1200.0,"ABC Corporation Inc.", proShoes)
printMyActivity(Marc)
printMyActivity(MrBrown)
Observations:
- Functions are not associated to a type. Do not call a function over a method (
myobj.func(x,y)) but rather you pass the object as a parameter (func(myobj, x, y)) - Julia doesn't use inheritance, but rather composition (a field of the subtype is of the higher type, allowing access to its fields).
Some useful functions:
supertype(MyType): Returns the parent types of a type.subtypes(MyType): Lists all children of a type.fieldnames(MyType): Queries all the fields of a structure.isa(obj,MyType): Checks if obj is of type MyType.typeof(obj): Returns the type of obj.
I/O
Opening a file is similar to Python. The file closes automatically in the end:
# Write to file
open("file.txt", "w") do f # "w" for writing, "r" for read and "a" for append.
write(f, "test\n") # \n for newline
end
# Read whole file:
open("file.txt", "r") do f
filecontent = read(f,String)
print(filecontent)
end
# Read line by line:
open("file.txt", "r") do f
for ln in eachline(f)
println(ln)
end
end
# Read, keeping track of line numbers:
open("file.txt", "r") do f
for (i,ln) in enumerate(eachline(f))
println("$i $ln")
end
end
Metaprogramming
TODO
Exceptions
Exceptions are similar to Python:
try
# Some dangerous code...
catch
# What to do if an error happens, most likely send an error message using:
error("My detailed message")
end
# Check for specific exception:
function volume(region, year)
try
return data["volume",region,year]
catch e
if isa(e, KeyError)
return missing
end
rethrow(e)
end
end
REPL
One can load a Julia file into the REPL to experiment with it:
include("my_file.jl")
DataFrames
Examples:
# Read data from a CSV
using DataFrames, CSV
myData = CSV.read(file, DataFrame, header = 1, copycols = true, types=Dict(:column_name => Int64))
# Read data from the web:
using DataFrames, HTTP, CSV
resp = HTTP.request("GET", "https://data.cityofnewyork.us/api/views/kku6-nxdu/rows.csv?accessType=DOWNLOAD")
df = CSV.read(IOBuffer(String(resp.body)))
# Read data from spreadsheet:
using DataFrames, OdsIO
df = ods_read("spreadsheet.ods";sheetName="Sheet2",retType="DataFrame",range=((tl_row,tl_col),(br_row,br_col)))
# Empty df:
df = DataFrame(A = Int64[], B = Float64[])
Insights about the data:
first(df, 6)show(df, allrows=true, allcols=true)last(df, 6)describe(df)unique(df.fieldName)or[unique(c) for c in eachcol(df)]names(df): Returns array of column names[eltype(col) for col = eachcol(df)]: Returns an array of column typessize(df): (r,c);size(df)[1]: (r);size(df)[2]: (c).ENV["LINES"] = 60: Change the default number of lines before the content is - truncated (default 30).for c in eachcol(df): Iterates over each column.for r in eachrow(df): iterates over each row.
To query the data from a DataFrame you can use the Query package. Examples:
using Query
dfOut = @from i in df begin
@where i.col1 > 1
@select {aNewColName=i.col1, i.col3}
@collect DataFrame
end
dfOut = @from i in df begin
@where i.value != 1 && i.cat1 in ["green","pink"]
@select i
@collect DataFrame
end
References
- Julia language: a concise tutorial.
- Antonello Lobianco. Julia Quick Syntax Reference. 1st Edition. Apress.
Notes on Julia Performance
Statically typing the program, or facilitating the type inference of the JIT compiler makes the code run faster. Some notes:
- Avoid global variables and run your performance-critical code within functions rather than in the global scope;
- Annotate the inner type of a container, so it can be stored in memory contiguously;
- Annotate the fields of composite types (use eventually parametric types);
- Loop matrices first by column and then by row.
Notes on profiling :
- To time a part of the code type
@time myFunc(args)(be sure you ran that function at least once, or you will measure compile time rather than run-time). @benchmark myFunc(args)(from package BenchmarkTools) also works.- Profile a function:
Profile.@profile myfunct()(best after the function has been already ran once for JIT-compilation). - Print the profiling results:
Profile.print()(number of samples in corresponding line and all downstream code; file name:line number; function name;) - Explore a chart of the call graph with profiled data:
ProfileView.view()(from package ProfileView). - Clear profile data:
Profile.clear().
Julia Plotting
The Plots package provides an unified API to several supported backends. Install the packages "Plots" and at least one backend, like PlotlyJS or PyPlot.jl. Example:
using Plots
plotlyjs()
plot(sin, -2pi, pi, label="sine function")
Notes on Python
Python is a high-level, dynamically and strongly typed, garbage-collected, general-purpose programming language. It supports multiple programming paradigms, including structured (particularly procedural), object-oriented programming, functional programming and aspect-oriented programming (including metaprogramming and metaobjects). It is often described as a "batteries included" language due to its comprehensive standard library.
Python uses dynamic typing and a combination of reference counting and a cycle-detecting garbage collector for memory management. It uses dynamic name resolution (late binding), which binds method and variable names during program execution.
Its design offers some support for functional programming in the Lisp tradition. It has filter, map and reduce functions; list comprehensions, dictionaries, sets, and generator expressions. The standard library has two modules (itertools and functools) that implement functional tools borrowed from Haskell and Standard ML.
Its core philosophy is summarized in the Zen of Python (PEP 20), which includes aphorisms such as:
- Beautiful is better than ugly.
- Explicit is better than implicit.
- Simple is better than complex.
- Complex is better than complicated.
- Readability counts.
Implementations
CPython is the reference implementation of Python. It is written in C, meeting the C11 standard (beginning with Python 3.11). It compiles Python programs into an intermediate bytecode which is then executed by its virtual machine. CPython is distributed with a large standard library written in a mixture of C and native Python, and is available for many platforms.
Other implementations are:
- PyPy, a fast, compliant interpreter of Python 2.7 and 3.8. Its just-in-time compiler often brings a significant speed improvement over CPython but some libraries written in C cannot be used with it.
- Stackless Python, a significant fork of CPython that implements microthreads; it does not use the call stack in the same way, thus allowing massively concurrent programs. PyPy also has a stackless version.
- Pyston, a variant of the Python runtime that uses just-in-time compilation to speed up the execution of Python programs.
- Cinder, a performance-oriented fork of CPython 3.8 that contains a number of optimizations, including bytecode inline caching, eager evaluation of coroutines, a method-at-a-time JIT, and an experimental bytecode compiler.
- Codon, that compiles a subset of statically typed Python to machine code (via LLVM) and supports native multithreading.
- Cython, that compiles (a superset of) Python to C. The resulting code is also usable with Python via direct C-level API calls into the Python interpreter.
- PyJL, that compiles/transpiles a subset of Python to "human-readable, maintainable, and high-performance Julia source code".
- Nuitka, that compiles Python into C.
- Numba, that uses LLVM to compile a subset of Python to machine code.
- Pythran, that compiles a subset of Python 3 to C++ 11.
Python Deep Dive
TODO
Python Performance
TODO
Python Tips
Table of Contents
- Python Tips
General Project Guidance
Project Layout
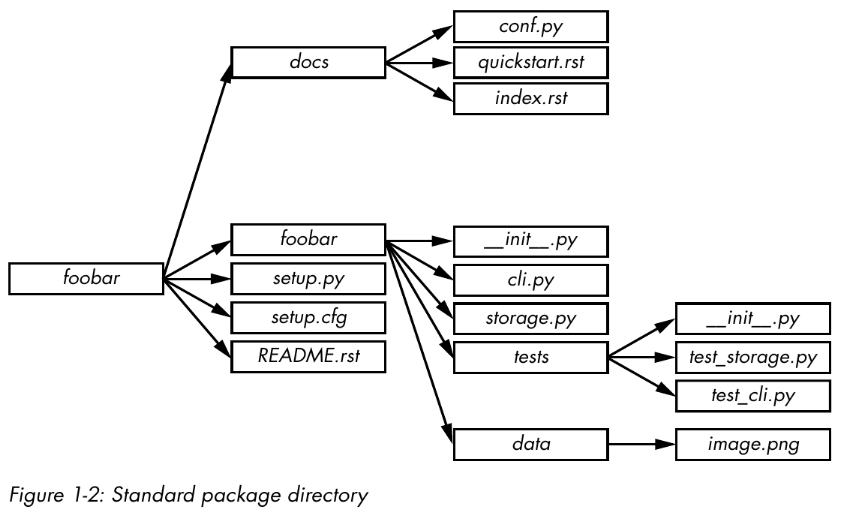
Avoid storing unit tests outside the package directory. These tests should be included in a subpackage of your software so that they aren’t automatically installed as a tests top-level module by setuptools (or some other packaging library) by accident. By placing them in a subpackage, you ensure they can be installed and eventually used by other packages so users can build their own unit tests.
Note that using setup.py is highly unadvised as it introduces arbitrary code into the build process. Also, executing the setup.py directly is deprecated.
Some optional folders can also appear:
etcfor sample configuration filestoolsfor shell scripts or related toolsbinfor binary scripts you’ve written that will be installed by setup.py
Organize the code based on features, not on file types. Don't create functions.py or exceptions.py files, but rather api.py or time_travel.py files.
Don't create a module folder which only contains an __init__.py file. If you create a module folder, it should contain several files that belong to it's category.
Be careful about the code that you put in the __init__.py file. This file will be called and executed the first time that a module contained in the directory is loaded. Placing the wrong things in your __init__.py can have unwanted side effects. In fact, __init__.py files should be empty most of the time. Don’t try to remove __init__.py files altogether though, or you won’t be able to import your Python module at all: Python requires an __init__.py file to be present for the directory to be considered a submodule.
Versioning
Two main ways to version Python software:
PEP 440 / PyPA Guidelines
It must obey the following regex: N[.N]+[{a|b|c|rc}N][.postN][.devN]
This means versions such as 1.2.0 and 0.4.7 are allowed. Also:
- Version
1.3.0is quivalent to1.3 - Versions matching
N[.N]+(no suffix) are considered final releases. N[.N]+aN(e.g.,1.2a1) denotes an alpha release, i.e., a version that might be unstable and missing features.N[.N]+bN(e.g.,1.2b1) denotes a beta release, i.e., a version that might be feature complete but still buggy.N[.N]+rcN(e.g.,0.4rc1) denotes a release candidate, i.e., a version that might be released as the final product unless significant bugs emerge.- The suffix
.postN(e.g.,1.4.post2) indicates a post release. Post releases are typically used to address minor errors in the publication process, such as mistakes in release notes. You shouldn’t use the .postN suffix when releasing a bug-fix version, instead, increment the minor version number. - The suffix
.devN(e.g.,2.3.4.dev3) indicates a developmental release. It indicates a prerelease of the version that it qualifies: e.g., 2.3.4.dev3 indicates the third developmental version of the 2.3.4 release, prior to any alpha, beta, candidate, or final release. This suffix is discouraged because it is harder for humans to parse.
More details here.
Semantic Versioning
Given a version number MAJOR.MINOR.PATCH (X.Y.Z), increment the:
MAJORversion when you make incompatible API changesMINORversion when you add functionality in a backward compatible mannerPATCHversion when you make backward compatible bug fixes
Software using Semantic Versioning MUST declare a public API. This API could be declared in the code itself or exist strictly in documentation. However it is done, it SHOULD be precise and comprehensive.
A normal version number MUST take the form X.Y.Z where X, Y, and Z are non-negative integers, and MUST NOT contain leading zeroes. X is the major version, Y is the minor version, and Z is the patch version. Each element MUST increase numerically. For instance: 1.9.0 -> 1.10.0 -> 1.11.0.
Once a versioned package has been released, the contents of that version MUST NOT be modified. Any modifications MUST be released as a new version.
Major version zero (0.y.z) is for initial development. Anything MAY change at any time. The public API SHOULD NOT be considered stable.
Version 1.0.0 defines the public API. The way in which the version number is incremented after this release is dependent on this public API and how it changes.
Patch version Z (x.y.Z | x > 0) MUST be incremented if only backward compatible bug fixes are introduced. A bug fix is defined as an internal change that fixes incorrect behavior.
Minor version Y (x.Y.z | x > 0) MUST be incremented if new, backward compatible functionality is introduced to the public API. It MUST be incremented if any public API functionality is marked as deprecated. It MAY be incremented if substantial new functionality or improvements are introduced within the private code. It MAY include patch level changes. Patch version MUST be reset to 0 when minor version is incremented.
Major version X (X.y.z | X > 0) MUST be incremented if any backward incompatible changes are introduced to the public API. It MAY also include minor and patch level changes. Patch and minor versions MUST be reset to 0 when major version is incremented.
A pre-release version MAY be denoted by appending a hyphen and a series of dot separated identifiers immediately following the patch version. Identifiers MUST comprise only ASCII alphanumerics and hyphens [0-9A-Za-z-]. Identifiers MUST NOT be empty. Numeric identifiers MUST NOT include leading zeroes. Pre-release versions have a lower precedence than the associated normal version. A pre-release version indicates that the version is unstable and might not satisfy the intended compatibility requirements as denoted by its associated normal version. Examples: 1.0.0-alpha, 1.0.0-alpha.1, 1.0.0-0.3.7, 1.0.0-x.7.z.92, 1.0.0-x-y-z.--.
Build metadata MAY be denoted by appending a plus sign and a series of dot separated identifiers immediately following the patch or pre-release version. Identifiers MUST comprise only ASCII alphanumerics and hyphens [0-9A-Za-z-]. Identifiers MUST NOT be empty. Build metadata MUST be ignored when determining version precedence. Thus two versions that differ only in the build metadata, have the same precedence. Examples: 1.0.0-alpha+001, 1.0.0+20130313144700, 1.0.0-beta+exp.sha.5114f85, 1.0.0+21AF26D3----117B344092BD.
More details here.
Linting and Formating
Use PEP8 to ensure good style of your code:
- Use four spaces per indentation level.
- Limit all lines to a maximum of 79 characters (this is debatable).
- Separate top-level function and class definitions with two blank lines.
- Encode files using ASCII or UTF-8.
- Use one module import per import statement and per line. Place import statements at the top of the file, after comments and docstrings, grouped first by standard, then by third party, and finally by local library imports.
- Do not use extraneous whitespaces between parentheses, square brackets, or braces or before commas.
- Write class names in camel case (e.g.,
CamelCase), suffix exceptions withError(if applicable), name functions in lowercase with words and underscores (e.g.,my_function) and use a leading underscore for_privateattributes or methods.
One should run linters, type checkers and formaters directly from the code editor and on CI/CD pipelines.
Ruff
Ruff is an extremely fast Python linter and formatter, written in Rust. Ruff can be used to replace Black, Flake8 (plus dozens of plugins), isort, pydocstyle, pyupgrade, and more. It can be used on VSCode or on a pipeline.
Usage as a linter:
ruff check . # Lint all files in the current directory (and any subdirectories).
ruff check path/to/code/ # Lint all files in `/path/to/code` (and any subdirectories).
ruff check path/to/code/*.py # Lint all `.py` files in `/path/to/code`.
ruff check path/to/code/to/file.py # Lint `file.py`.
ruff check @arguments.txt # Lint using an input file, treating its contents as newline-delimited command-line arguments.
Usage as a formatter:
ruff format . # Format all files in the current directory (and any subdirectories).
ruff format path/to/code/ # Format all files in `/path/to/code` (and any subdirectories).
ruff format path/to/code/*.py # Format all `.py` files in `/path/to/code`.
ruff format path/to/code/to/file.py # Format `file.py`.
ruff format @arguments.txt # Format using an input file, treating its contents as newline-delimited command-line arguments.
Usage as a Github Action:
name: Ruff
on: [ push, pull_request ]
jobs:
ruff:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: chartboost/ruff-action@v1
Configuration
Ruff can be configured through a pyproject.toml, ruff.toml, or .ruff.toml file (see: Configuration, or Settings for a complete list of all configuration options).
If left unspecified, Ruff's default configuration is equivalent to:
[tool.ruff]
# Exclude a variety of commonly ignored directories.
exclude = [
".bzr",
".direnv",
".eggs",
".git",
".git-rewrite",
".hg",
".ipynb_checkpoints",
".mypy_cache",
".nox",
".pants.d",
".pyenv",
".pytest_cache",
".pytype",
".ruff_cache",
".svn",
".tox",
".venv",
".vscode",
"__pypackages__",
"_build",
"buck-out",
"build",
"dist",
"node_modules",
"site-packages",
"venv",
]
# Same as Black.
line-length = 88
indent-width = 4
# Assume Python 3.8
target-version = "py38"
[tool.ruff.lint]
# Enable Pyflakes (`F`) and a subset of the pycodestyle (`E`) codes by default.
select = ["E4", "E7", "E9", "F"]
ignore = []
# Allow fix for all enabled rules (when `--fix`) is provided.
fixable = ["ALL"]
unfixable = []
# Allow unused variables when underscore-prefixed.
dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
[tool.ruff.format]
# Like Black, use double quotes for strings.
quote-style = "double"
# Like Black, indent with spaces, rather than tabs.
indent-style = "space"
# Like Black, respect magic trailing commas.
skip-magic-trailing-comma = false
# Like Black, automatically detect the appropriate line ending.
line-ending = "auto"
Some configuration options can be provided via the command-line, such as those related to rule enablement and disablement, file discovery, and logging level:
ruff check path/to/code/ --select F401 --select F403 --quiet
See ruff help for more on Ruff's top-level commands, or ruff help check and ruff help format
for more on the linting and formatting commands, respectively.
Ruff supports over 700 lint rules, many of which are inspired by popular tools like Flake8, isort, pyupgrade, and others. Regardless of the rule's origin, Ruff re-implements every rule in Rust as a first-party feature.
By default, Ruff enables Flake8's F rules, along with a subset of the E rules, omitting any stylistic rules that overlap with the use of a formatter, like ruff format or Black.
If you're just getting started with Ruff, the default rule set is a great place to start: it catches a wide variety of common errors (like unused imports) with zero configuration.
For a complete enumeration of the supported rules, see Rules.
PyRight
My choice on static checking for Python. More information here.
Modules, Libraries and Frameworks
Importing
The import keyword is actually a wrapper around a function named __import__.
>>> import itertools
>>> itertools
# <module 'itertools' from '/usr/.../>
is equivalent to
>>> itertools = __import__("itertools")
>>> itertools
# <module 'itertools' from '/usr/.../>
also, it's possible to
>>> it = __import__("itertools")
>>> it
# <module 'itertools' from '/usr/.../>
Modules, once imported, are essentially objects whose attributes are objects.
sys Module
The sys module provides access to variables and functions related to Python itself and the operating system it is running on. you can retrieve the list of modules currently imported using the sys.modules variable, which is a dictionary whose key is the module name you want to inspect and whose returned value is the module object. Calling sys.modules.keys(), for example, will return the complete list of the names of loaded modules.
You can also retrieve the list of modules that are built-in by using the sys.builtin_module_names variable. The built-in modules compiled to your interpreter can vary depending on what compilation options were passed to the Python build system.
Import Paths
When importing modules, Python relies on a list of paths to know where to look for the module. This list is stored in the sys.path variable.You can change this list, adding or removing paths as necessary, or even modify the PYTHONPATH environment variable. Adding paths to the sys.path variable can be useful if you want to install Python modules to nonstandard locations, such as a test environment. Note that the list will be iterated over to find the requested module, so the order of the paths in sys.path is important.
Your current directory is searched before the Python Standard Library directory. That means that if you decide to name one of your scripts random.py and then try using import random, the file from your current directory will be imported rather than the Python module.
Useful Standard Libraries
atexitallows you to register functions for your program to call when it exits;argparseprovides functions for parsing command line arguments;bisectprovides bisection algorithms for sorting lists;calendarprovides a number of date-related functions;codecsprovides functions for encoding and decoding data;collectionsprovides a variety of useful data structures;copyprovides functions for copying data;csvprovides functions for reading and writing CSV files;datetimeprovides classes for handling dates and times;fnmatchprovides functions for matching Unix-style filename patterns;concurrentprovides asynchronous computation;globprovides functions for matching Unix-style path patterns;ioprovides functions for handling I/O streams. In Python 3, it also contains StringIO, which allows you to treat strings as files;jsonprovides functions for reading and writing data in JSON format;loggingprovides access to Python’s own built-in logging functionality;multiprocessingallows you to run multiple subprocesses from your application, while providing an API that makes them look like threads;operatorprovides functions implementing the basic Python operators, which you can use instead of having to write your own lambda expressions;osprovides access to basic OS functions;randomprovides functions for generating pseudorandom numbers;reprovides regular expression functionality;schedprovides an event scheduler without using multithreading;selectprovides access to the select() and poll() functions for creating event loops;shutilprovides access to high-level file functions;signalprovides functions for handling POSIX signals;tempfileprovides functions for creating temporary files and directories;threadingprovides access to high-level threading functionality;urllibprovides functions for handling and parsing URLs;uuidallows you to generate Universally Unique Identifiers (UUIDs);
Documentation
Your project documentation should always include the following on a README.md file:
- The problem your project is intended to solve, in one or two sentences.
- The license your project is distributed under. If your software is open source, you should also include this information in a header in each code file; just because you’ve uploaded your code to the Internet doesn’t mean that people will know what they’re allowed to do with it.
- A small example of how your code works.
- Installation instructions.
- Links to community support, mailing list, IRC, forums, and so on.
- A link to your bug tracker system.
- A link to your source code so that developers can download and start delving into it right away.
Also, it's useful to have a CONTRIBUTING.md file that will be displayed when someone submits a pull request. It should provide a checklist for users to follow before they submit the PR, including things like whether your code follows PEP 8 and reminders to run the unit tests.
Some documentation software:
- Sphinx reads Markdown (through MyST) or reStructuredText and produces HTML or PDF documentation.
- mdBook reads Markdown and produces HTML or PDF documentation.
Documenting API Changes
Whenever you make changes to an API, the first and most important thing to do is to heavily document them so that a consumer of your code can get a quick overview of what’s changing. Your document should cover:
- New elements of the new interface
- Elements of the old interface that are deprecated
- Instructions on how to migrate to the new interface
Make sure that you don’t remove the old interface right away. I recommend keeping the old interface until it becomes too much trouble to do so. If you have marked it as deprecated, users will know not to use it. Example:
class Car(object):
def turn_left(self):
"""Turn the car left.
.. deprecated:: 1.1
Use :func:`turn` instead with the direction argument set to left
"""
self.turn(direction='left')
def turn(self, direction):
"""Turn the car in some direction.
:param direction: The direction to turn to.
:type direction: str
"""
pass
Python also provides the warnings module, which allows your code to issue various kinds of warnings when a deprecated function is called. These warnings, DeprecationWarning and PendingDeprecationWarning, can be used to tell the developer that a function they’re calling is deprecated or going to be deprecated, respectively. Example:
import warnings
class Car(object):
def turn_left(self):
"""Turn the car left.
.. deprecated:: 1.1
Use :func:`turn` instead with the direction argument set to left
"""
warnings.warn("turn_left is deprecated; use turn instead", DeprecationWarning)
self.turn(direction='left')
def turn(self, direction):
"""Turn the car in some direction.
:param direction: The direction to turn to.
:type direction: str
"""
pass
Python 2.7 and later versions, by default, do not print any warnings emitted by the warnings module.The option -W all will print all warnings to stderr, which can be a good way to catch warnings and fix them early on when running a test suite. Debtcollector can automate some of this.
Diátaxis
TODO
Generating Documentation from Docstrings
TODO
Doctesting
TODO
Release Engineering
PyPA recommends Setuptools to package Python software. For what is worth, I recommend Poetry.
Poetry
TODO
Tox
TODO
The Abstract Syntax Tree
TODO
Bibliography
- Julien Danjou. Serious Python. No Starch Press, 2019.
Python Libraries
Python's large standard library provides tools suited to many tasks and is commonly cited as one of its greatest strengths. For Internet-facing applications, many standard formats and protocols such as MIME and HTTP are supported. It includes modules for creating graphical user interfaces, connecting to relational databases, generating pseudorandom numbers, arithmetic with arbitrary-precision decimals, manipulating regular expressions, and unit testing.
Some parts of the standard library are covered by specifications—for example, the Web Server Gateway Interface (WSGI) implementation wsgiref follows PEP 333 — but most are specified by their code, internal documentation, and test suites. However, because most of the standard library is cross-platform Python code, only a few modules need altering or rewriting for variant implementations.
Notes on Numpy
Basics
Basic functions:
import numpy as np
# Creating arrays
np.array([1000, 2300, 4987, 1500]) # Create array from list: array([1000, 2300, 4987, 1500])
np.arange(10) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(10, 25, 5) # array([10, 15, 20])
np.loadtxt(fname='file.txt', dtype=int) # Creates an array of ints with the contents of file.txt
np.zeros((m, n)) # Create an array of zeros with shape (m, n)
np.ones((m, n),dtype=np.int16) # Create an array of ones with shape (m, n) and type dtype
np.linspace(0,2,9) # Create an array of evenly spaced values: array([0., 0.25, 0.5 , 0.75, 1., 1.25, 1.5, 1.75, 2.])
np.full((m, n), a) # Create an array with shape (m, n) whose elements are always a
np.eye(m) # Create an identity matrix with dimension m
np.random.random((m, n)) # Create a random matrix with dimension (m, n). Random numbers between 0 and 1
np.empty((m, n)) # Create an empty array with dimension (m, n). The data is garbage.
# Attributes
data_array.dtype # Returns the type of the elements of data_array
data_array.shape # Returns the dimensions of the array
data_array.ndim # Returns the number of dimensions of the array
data_array.size # Returns the number of elements of the array
Operations with floats and integers broadcast to the whole array:
a = np.ones(4, dtype=int)
a/2
# >>> array([0.5, 0.5, 0.5, 0.5])
Selecting data:
a = np.random.random((2, 2))
a[1, 1] # Returns the element on the second line and second column
a[-1] # Returns the last line
b = np.random.random((10))
b[1:4] # Returns the elements with index 1, 2 and 3
# The syntax is array[min:max:step]. min is 0 by default, max is not included.
b[:4:2] # Returns the elements with index 0 and 2
c = np.random.random((10, 10))
c[:, 1:3] # Returns the columns 1 and 2 of all the lines
c[:4, ::2] # Returns the first 4 lines (indexes 0, 1, 2 and 3) with columns jumped by 2 (indexes 0, 2, 4, 6, 8)
Verifying conditions:
a = np.random.random((4))
a > 1 # Returns a boolean array: array([False, False, False, False])
a[a > 0.5] # Returns an array containing all numbers that obey the condition
Some methods:
a.T # Returns the transpose of the array
a.tolist() # Converts the array to a list
a.reshape((m, n), order='C') # Reorganizes the array into a new array with dimensions (m, n)
# Example:
a = np.arange(10)
a.reshape((5, 2), order='C') # >>> array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]])
a.reshape((5, 2), order='F') # >>> array([[0, 5], [1, 6], [2, 7], [3, 8], [4, 9]])
# array + array is element-wise sum of arrays
# list + list is concatenation of lists
np.column_stack((a, b, c)) # Take a tuple of 1D arrays and stack them as columns to make a single 2D array.
np.sum(a[:,2]) # Returns the sum of all the elements of the slice
Some basic statistics:
np.mean(a) # Returns the mean of all the elements of the array
np.mean(a[:, 2]) # Returns the mean of all the elements of the slice
np.mean(a, axis=0) # Returns the mean of all the elements of the array in the axis 0
np.std(a[:,2]) # Returns the standard deviation of the slice
Notes on Rust
Table of Contents
Basics
Rust's philosophy:
- Strictly enforcing safe borrowing of data
- Functions, methods and closures to operate on data
- Tuples, structs and enums to aggregate data
- Pattern matching to select and destructure data
- Traits to define behavior on data
// Hello world fn main() { println!(“Hello!”); }
Functions to write strings:
format!: write formatted text to Stringprint!: same as format! but the text is printed to the console (io::stdout).println!: same as print! but a newline is appended.eprint!: same as format! but the text is printed to the standard error (io::stderr).eprintln!: same as eprint! but a newline is appended.
Ways to print to stdout:
fn main() { println!(“Today is {}”, 20); // By variable let name = "world"; println!("Hello {name}!"); // By positional argument println!("{0}, this is {1}. {1}, this is {0}", "Alice", "Bob"); // By naming the arguments println!("{subject} {verb} {object}", object="the lazy dog",subject="the quick brown fox", verb="jumps over"); // By right-aligning a text with a specified width println!("{number:>width$}", number=1, width=6); // By padding numbers with extra zeroes println!("{number:>0width$}", number=1, width=6); // By rounding floats let pi = 3.141592; println!("Pi is roughly {:.3}", pi); }
Tests:
fn main() { // Checks if x is equal to y. If not, panic. assert_eq!(x, y); // Checks if x is not equal to y. If not, panic. assert_neq!(x, y); // Checks if expression is true. If not, panic. assert!(expression); }
Commentaries:
fn main() { // Regular commentary. /* Multi-line Commentary */ /// Commentary that will become documentation with cargo doc --open /// It accepts markdown /// And can contain tests: /// /// ``` /// use my_lib::*; /// /// assert_eq!(3, soma(1, 2)); /// ``` pub fn soma(x: i32, y: i32) -> i32 { x + y } }
The build system and dependency manager is called cargo:
# Creates a new project
cargo new [name]
# Create a new project without git
cargo new --vcs=none [name]
# Compiles
cargo build
# Compiles with optimizations
cargo build --release
# Checks for syntax errors
cargo check
# Compiles and executes
cargo run
# Updates the dependencies. Doesn't bump major version
cargo update
# Creates documentation
cargo doc --open
# Linting
cargo fmt
cargo fix
cargo clippy
You can make Clippy pedantic by adding the following at the first line of the main.rs file:
#![allow(unused)] #![warn(clippy::all, clippy::pedantic)] fn main() { }
Declaration of variables:
fn main() { // Immutable variable let a = 1; // Mutable variable let mut b = 2; // Constant with type annotation const CTE: u32 = 100; // It is possible to do shadowing. The final value o x is 6 let x = 5; let x = x + 1; }
For integers, we have i8, i16, i32, i64, i128 and u8, u16, u32, u64, u128 for unsigned. For floats, f32 and f64. i32 and f64 are the default types.
The usual operators are present: + - * / %
The underscore _ means to throw away something:
#![allow(unused)] fn main() { // this does nothing because 42 is a constant let _ = 42; // this calls `get_thing` but throws away its result let _ = get_thing(); // Starting with an underscore means the compiler won't warn about them being unused: let _x = 42; }
Tuples:
fn main() { // Doesn't grow in size let tup: (i32, f64, u8) = (500, 6.4, 1); // Destructuring let (x, y, z) = tup; println!("The value of y is: {}", y); // Destructuring only a part of it let (_, _, one) = tup; // By index let five_hundred = tup.0; }
Arrays:
fn main() { // Doesn't grow in size. All elements of the same type. let a = [1, 2, 3, 4, 5]; let first = a[0]; // Creates an array of 5 elements, each of which is 3 let a = [3; 5]; }
Structs:
#![allow(unused)] fn main() { // Declaration struct Vec2 { x: f64, y: f64, } // Initialization // The order does not matter, only the names do let v1 = Vec2 { x: 1.0, y: 3.0 }; let v2 = Vec2 { y: 2.0, x: 4.0 }; // Initializing the rest of the fields from another struct let v3 = Vec2 { x: 14.0, ..v2 }; let v4 = Vec2 { ..v3 }; // Destructuring // `x` is now 1.0, `y` is now `3.0` let Vec2 { x, y } = v1; // This throws away `v.y` let Vec2 { x, .. } = v; // A tuple struct struct Point2D(u32, u32); // A unit struct struct Unit; }
Tuple structs are similar to classic structs, but their fields have no names. For accessing individual variables, the same syntax is used as with regular tuples, namely, foo.0, foo.1, and so on, starting at zero. Unit structs are most commonly used as markers. They're useful when you need to implement a trait on something but don't need to store any data inside it.
fn main() { // Instantiate a classic struct, with named fields. Order does not matter. let person = Person { name: String::from("Adam"), likes_oranges: true, age: 25 }; // Instantiate a tuple struct by passing the values in the same order as defined. let origin = Point2D(0, 0) // Instantiate a unit struct. let unit = Unit; }
Functions:
#![allow(unused)] fn main() { fn my_function(arg1: type1, arg2: type2) -> return_type { //body } }
You can declare methods on your own types:
#![allow(unused)] fn main() { struct Number { odd: bool, value: i32, } impl Number { fn is_strictly_positive(self) -> bool { self.value > 0 } } }
Traits are something multiple types can have in common. You can implement:
- One of your traits on anyone's type
- Anyone's trait on one of your types
- But not a foreign trait on a foreign type
#![allow(unused)] fn main() { struct Number { odd: bool, value: i32, } trait Signed { fn is_strictly_negative(self) -> bool; } // Our trait on our type impl Signed for Number { fn is_strictly_negative(self) -> bool { self.value < 0 } } // Our trait on a foreign type impl Signed for i32 { fn is_strictly_negative(self) -> bool { self < 0 } } // A foreign trait on our type: // The `Neg` trait is used to overload `-`, the unary minus operator. // An impl block is always for a type, so, inside that block, Self means that type. impl std::ops::Neg for Number { type Output = Self; fn neg(self) -> Self { Self { value: -self.value, odd: self.odd, } } } }
Some traits are markers - they don't say that a type implements some methods, they say that certain things can be done with a type:
fn main() { // i32 implements trait Copy (in short, i32 is Copy): let a: i32 = 15; let b = a; // `a` is copied let c = a; // `a` is copied again print_i32(a); // `a` is copied again // The Number struct is not Copy, so this doesn't work: let n = Number { odd: true, value: 51 }; let m = n; // `n` is moved into `m` let o = n; // error: use of moved value: `n` // It works if print_number takes an immutable reference instead: print_number(&n); // `n` is borrowed for the time of the call print_number(&n); // `n` is borrowed again // It also works if a function takes a mutable reference - but only if our variable binding is also mut: let mut m = Number { odd: true, value: 51 }; print_number(&m); invert(&mut m); // `m is borrowed mutably - everything is explicit print_number(&m); } fn print_i32(x: i32) { println!("x = {}", x); } fn print_number(n: &Number) { println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value); } fn invert(n: &mut Number) { n.value = -n.value; }
Trait methods can also take self by reference or mutable reference:
#![allow(unused)] fn main() { impl std::clone::Clone for Number { fn clone(&self) -> Self { Self { ..*self } } } // Marker traits like Copy have no methods: // `Copy` requires that `Clone` is implemented too. // Number values will no longer be moved, but copied. impl std::marker::Copy for Number {} }
When invoking trait methods, the receiver is borrowed implicitly:
fn main() { let n = Number { odd: true, value: 51 }; let mut m = n.clone(); m.value += 100; print_number(&n); print_number(&m); }
Some traits are so common, they can be implemented automatically by using the derive attribute:
#![allow(unused)] fn main() { #[derive(Clone, Copy)] struct Number { odd: bool, value: i32, } }
Functions can be generic:
#![allow(unused)] fn main() { fn foobar<T>(arg: T) { // do something with `arg` } // Multiple type parameters: fn foobar<L, R>(left: L, right: R) { // do something with `left` and `right` } }
Type parameters can have constraints:
fn print<T: Display>(value: T) { println!("value = {}", value); } fn print<T: Debug>(value: T) { println!("value = {:?}", value); } // Longer syntax: fn print<T>(value: T) where T: Display, { println!("value = {}", value); } // If you want multiple constraints: use std::fmt::Debug; fn compare<T>(left: T, right: T) where T: Debug + PartialEq, { println!("{:?} {} {:?}", left, if left == right { "==" } else { "!=" }, right); } fn main() { compare("tea", "coffee"); // prints: "tea" != "coffee" }
Generic functions can be navigated using ::
fn main() { use std::any::type_name; // Turbofish syntax println!("{}", type_name::<i32>()); // prints "i32" println!("{}", type_name::<(f64, char)>()); // prints "(f64, char)" }
Structs can be generic:
struct Pair<T> { a: T, b: T, } fn print_type_name<T>(_val: &T) { println!("{}", std::any::type_name::<T>()); } fn main() { let p1 = Pair { a: 3, b: 9 }; let p2 = Pair { a: true, b: false }; print_type_name(&p1); // prints "Pair<i32>" print_type_name(&p2); // prints "Pair<bool>" // Vec is generic let mut v1 = Vec::new(); v1.push(1); let mut v2 = Vec::new(); v2.push(false); }
Enums are types that can only have some specific values
fn main() { enum WebEvent { // An `enum` may either be `unit-like`, PageLoad, PageUnload, // like tuple structs, KeyPress(char), Paste(String), // or c-like structures. Click { x: i64, y: i64 }, } }
Vectors:
fn main() { // Vec is generic let mut v1 = Vec::new(); v1.push(1); let mut v2 = Vec::new(); v2.push(false); // Literals: let v1 = vec![1, 2, 3]; let v2 = vec![true, false, true]; }
Hash maps:
The type HashMap<K, V> stores a mapping of keys of type K to values of type V.
fn main() { use std::collections::HashMap; let mut contacts = HashMap::new(); contacts.insert("Daniel", "798-1364"); contacts.insert("Ashley", "645-7689"); contacts.insert("Katie", "435-8291"); contacts.insert("Robert", "956-1745"); // Search for "Daniel" on contacts match contacts.get(&"Daniel") { Some(&number) => println!("Calling Daniel: {}", call(number)), _ => println!("Don't have Daniel's number."), } // Remove "Ashley" from contacts contacts.remove(&"Ashley"); // `HashMap::iter()` returns an iterator that yields // (&'a key, &'a value) pairs in arbitrary order. for (contact, &number) in contacts.iter() { println!("Calling {}: {}", contact, call(number)); } }
Conditional:
#![allow(unused)] fn main() { if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } let number = if condition { 5 } else { 6 }; }
Match:
// Similar to switch in C, but more powerful match feeling_lucky { true => 6, false => 4, } /*******************************************************/ struct Number { odd: bool, value: i32, } fn main() { let one = Number { odd: true, value: 1 }; let two = Number { odd: false, value: 2 }; print_number(one); print_number(two); } fn print_number(n: Number) { match n { Number { odd: true, value } => println!("Odd number: {}", value), Number { odd: false, value } => println!("Even number: {}", value), } } /*******************************************************/ // A match has to be exhaustive: at least one arm needs to match. fn print_number(n: Number) { match n { Number { value: 1, .. } => println!("One"), Number { value: 2, .. } => println!("Two"), Number { value, .. } => println!("{}", value), // If the last arm didn't exist, we would get a compile-time error } } /*******************************************************/ // _ can be used as a "catch-all" pattern: fn print_number(n: Number) { match n.value { 1 => println!("One"), 2 => println!("Two"), _ => println!("{}", n.value), } }
Loop:
#![allow(unused)] fn main() { // Infinite loop loop { // body } // result is 20 let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; while number != 0 { println!("{}!", number); number -= 1; } let a = [10, 20, 30, 40, 50]; for element in a.iter() { println!("the value is: {}", element); } for number in (1..4).rev() { println!("{}!", number); } }
A pair of brackets declares a block, which has its own scope:
// This prints "in", then "out" fn main() { let x = "out"; { // this is a different `x` let x = "in"; println!(x); } println!(x); }
Blocks are also expressions, which mean they evaluate to a value.
#![allow(unused)] fn main() { // This: let x = 42; // Is equivalent to this: let x = { 42 }; }
Inside a block, there can be multiple statements:
#![allow(unused)] fn main() { let x = { let y = 1; // First statement let z = 2; // Second statement y + z // This is the tail - what the whole block will evaluate to }; }
That's why "omitting the semicolon at the end of a function" is the same as returning.
Importing and Namespaces
use directives can be used to "bring in scope" names from other namespace:
#![allow(unused)] fn main() { // std is a crate (~ a library), cmp is a module (~ a source file), and // min is a function: use std::cmp::min; let least = min(7, 1); // This is 1 }
Within use directives, curly brackets have another meaning: they're globs". If we want to import both min and max , we can do any of these:
#![allow(unused)] fn main() { // this works: use std::cmp::min; use std::cmp::max; // this also works: use std::cmp::{min, max}; // this also works! use std::{cmp::min, cmp::max}; }
A wildcard ( * ) lets you import every symbol from a namespace:
#![allow(unused)] fn main() { // This brings `min` and `max` in scope, and many other things use std::cmp::*; }
Panic, Options and Result
#![allow(unused)] fn main() { // Is a macro that violently stops execution with an error message, and the file name / line number of the error panic!("Error message"); // Option is a type that contains something, or nothing. If .unwrap() is called on it, and it contains nothing, it panics enum Option<T> { None, Some(T), } let o1: Option<i32> = Some(128); o1.unwrap(); // this is fine let o2: Option<i32> = None; o2.unwrap(); // this panics! // Result is an enum that can either contain something, or an error. It also panics when unwrapped and containing an error enum Result<T, E> { Ok(T), Err(E), } // get returns an option with the value if the index is inside of bounds let fruits = vec!["banana", "apple", "coconut", "orange", "strawberry"]; for index in 0..10 { match fruits.get(index) { Some(fruit_name) => println!("It's a delicious {}!", fruit_name), None => println!("There is no fruit! :("), } } let number = Some(7); // The `if let` construct reads: "if `let` destructures `number` into // `Some(i)`, evaluate the block (`{}`). if let Some(i) = number { println!("Matched {:?}!", i); } }
Lifetime
Variables have lifetimes:
fn main() { // `x` doesn't exist yet { // `x` starts existing let x = 42; // `x_ref` starts existing - it borrows `x` let x_ref = &x; println!("x = {}", x); // `x_ref` stops existing // `x` stops existing } // `x` no longer exists }
The lifetime of a reference cannot exceed the lifetime of the variable binding it borrows:
fn main() { let x_ref = { let x = 42; &x }; println!("x_ref = {}", x_ref); // error: `x` does not live long enough }
Memory
Stack and Heap
Both the stack and the heap are parts of memory that are available to your code to use at runtime, but they are structured in different ways. The stack is last in, first out. Adding data is called pushing onto the stack, and removing data is called popping off the stack. All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change must be stored on the heap instead. The heap is less organized: when you put data on the heap, you request a certain amount of space. The operating system finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. This process is called allocating on the heap and is sometimes abbreviated as just allocating. Pushing values onto the stack is not considered allocating. Because the pointer is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer. Pushing to the stack is faster than allocating on the heap because the operating system never has to search for a place to store new data; that location is always at the top of the stack. Comparatively, allocating space on the heap requires more work, because the operating system must first find a big enough space to hold the data and then perform bookkeeping to prepare for the next allocation. When your code calls a function, the values passed into the function (including, potentially, pointers to data on the heap) and the function’s local variables get pushed onto the stack. When the function is over, those values get popped off the stack. The stack is the memory set aside as scratch space for a thread of execution. When a function is called, a block is reserved on the top of the stack for local variables and some bookkeeping data. When that function returns, the block becomes unused and can be used the next time a function is called. The stack is always reserved in a LIFO (last in first out) order; the most recently reserved block is always the next block to be freed. This makes it really simple to keep track of the stack; freeing a block from the stack is nothing more than adjusting one pointer. The heap is memory set aside for dynamic allocation. Unlike the stack, there's no enforced pattern to the allocation and deallocation of blocks from the heap; you can allocate a block at any time and free it at any time. This makes it much more complex to keep track of which parts of the heap are allocated or free at any given time; there are many custom heap allocators available to tune heap performance for different usage patterns. Each thread gets a stack, while there's typically only one heap for the application (although it isn't uncommon to have multiple heaps for different types of allocation). The OS allocates the stack for each system-level thread when the thread is created. Typically the OS is called by the language runtime to allocate the heap for the application. The stack is attached to a thread, so when the thread exits the stack is reclaimed. The heap is typically allocated at application startup by the runtime, and is reclaimed when the application (technically process) exits. The size of the stack is set when a thread is created. The size of the heap is set on application startup, but can grow as space is needed (the allocator requests more memory from the operating system). The stack is faster because the access pattern makes it trivial to allocate and deallocate memory from it (a pointer/integer is simply incremented or decremented), while the heap has much more complex bookkeeping involved in an allocation or deallocation. Also, each byte in the stack tends to be reused very frequently which means it tends to be mapped to the processor's cache, making it very fast. Another performance hit for the heap is that the heap, being mostly a global resource, typically has to be multi-threading safe, i.e. each allocation and deallocation needs to be - typically - synchronized with "all" other heap accesses in the program.
Ownership
Each value in Rust has a variable that’s called its owner. There can only be one owner at a time. When the owner goes out of scope, the value will be dropped. Copies of heap objects are shallow, meaning that a new variable is just another pointer (on the stack) to the same heap address. The first pointer becomes stale.
#![allow(unused)] fn main() { let s1 = String::from("Hello!"); let s2 = s1; }
Stack variables are deep copied. They have a fixed size known in compile time. As a general rule, any group of simple scalar values can be Copy, and nothing that requires allocation or is some form of resource is Copy. Ex.: integers, floats, booleans, characters and tuples of these types. Passing a variable to a function will move or copy, just as assignment does:
fn main() { // s comes into scope let s = String::from("hello"); // s's value moves into the function and so is no // longer valid here takes_ownership(s); // x comes into scope let x = 5; // x would move into the function, but i32 is Copy, // so it’s okay to still use x afterward makes_copy(x); } // Here, x goes out of scope, then s. But because s's // value was moved, nothing special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{}", some_string); } // Here, some_string goes out of scope and `drop` is // called. The backing memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{}", some_integer); } // Here, some_integer goes out of scope. Nothing // special happens.
The ownership of a variable follows the same pattern every time: assigning a value to another variable moves it. When a variable that includes data on the heap goes out of scope, the value will be cleaned up by drop unless the data has been moved to be owned by another variable. At any given time, you can have either one mutable reference or any number of immutable references. References must always be valid.